Runs & Episodes
Runs and Episodes are the core abstractions for organizing your validation experiments in HumaLab.
Runs
A Run represents a complete validation experiment. It contains:
- A scenario definition
- Multiple episodes (individual executions)
- Metrics and statistics
- Metadata (name, description, tags)
Creating a Run
import humalab as hl
# Initialize HumaLab
with hl.init(api_key="your_api_key",
scenario={"param": "${uniform: 0, 10}"},
project="my_project",
name="my_run",
description="Testing parameter variations",
tags=["experiment", "v1"]) as run:
...Run Parameters
scenario(required): The Scenario instance defining the parameter spaceproject: Project name for organization (default: "default")name: Human-readable name for the rundescription: Detailed description of the runid: Custom run ID (auto-generated if not provided)tags: List of tags for categorizationbase_url: Custom API endpoint (optional)api_key: API key for authentication (optional, can usehl.init())timeout: Request timeout in seconds (optional)
Run Properties
# Access run metadata
print(run.id) # Unique run identifier
print(run.name) # Run name
print(run.description) # Run description
print(run.tags) # List of tags
print(run.project) # Project name
print(run.scenario) # Associated scenarioEpisodes
An Episode represents a single execution with a specific set of parameter values sampled from the scenario distributions.
Creating Episodes
# Create an episode within a run
with run.create_episode() as episode:
# Optionally specify an episode ID
with run.create_episode(episode_id="custom_episode_id") as episode:Episode Lifecycle
Episodes have a clear lifecycle with status tracking:
from humalab.humalab_api_client import EpisodeStatus
# Episode is created
with run.create_episode() as episode:
# Your validation logic
try:
# Execute your task
result = my_validation_function(episode.config)
# Log metrics
episode.log({"score": result.score})
# Successfully complete
episode.finish(status=EpisodeStatus.FINISHED)
except Exception as e:
# Handle errors
episode.finish(status=EpisodeStatus.ERRORED, err_msg=str(e))Episode Statuses
SUCCESS: Episode completed successfullyFAILED: Episode failedERRORED: Episode encountered an errorCANCELED: Episode was canceled
Accessing Episode Data
# Get the episode's unique identifier
print(episode.episode_id)
# Get the episode scenario
print(episode.scenario)
# Check if episode is finished
print(episode.is_finished)
# Get episode status
print(episode.status)Context Manager Pattern
The recommended way to use Runs is with Python's context manager:
with run:
for i in range(100):
with run.create_episode() as episode:
# Your validation code
result = validate(episode.scenario)
episode.log({"metric": result})
# Episode automatically finishes when exiting context
# Run automatically finishes when exiting contextThis ensures proper cleanup even if errors occur.
Multiple Episodes
Run multiple episodes to explore your scenario's parameter space:
with run:
for i in range(100):
with run.create_episode() as episode:
# Each episode gets different parameter values
# Access directly via episode attributes
# Run your validation
result = my_validation(episode)
# Log episode-specific data
episode.log({
"success": result.success,
"score": result.score
})Run-Level Logging
Log data at the run level (across all episodes):
# Create and add metrics at run level
metric = hl.metrics.Metrics()
run.add_metric("overall_score", metric)
# Log data to run-level metrics
for i in range(100):
with run.create_episode() as episode:
result = validate(episode)
# Log to run-level metric
run.log({"overall_score": result.score})Finishing Runs
Always finish your runs to ensure data is uploaded:
from humalab.humalab_api_client import RunStatus
# Successful completion (default)
run.finish()
# Or specify status explicitly
run.finish(status=RunStatus.FINISHED)
# Mark as errored with message
run.finish(status=RunStatus.ERRORED, err_msg="Something went wrong")
# Mark as canceled
run.finish(status=RunStatus.CANCELED)Run Statuses
FINISHED: Run completed successfullyERRORED: Run encountered an errorCANCELED: Run was canceled
Artifacts
Automatic Artifacts
HumaLab automatically uploads certain artifacts when a run finishes:
- scenario: The scenario YAML configuration is automatically saved
- seed: The random seed (if provided) is automatically saved for reproducibility
These are uploaded when you call run.finish() or when exiting a context manager.
with hl.init(
project="my_project",
scenario={"param": "${uniform: 0, 10}"},
seed=42 # This seed is automatically uploaded
) as run:
# Your code here
pass
# When the run finishes, both scenario YAML and seed are uploadedCode Artifacts
You can also manually log code artifacts to track versions:
# Log code content
with open("agent.py", "r") as f:
code = f.read()
run.log_code(key="agent_code", code_content=code)Note: The names scenario and seed are reserved and cannot be used for custom artifacts or metrics.
Scenario GUI
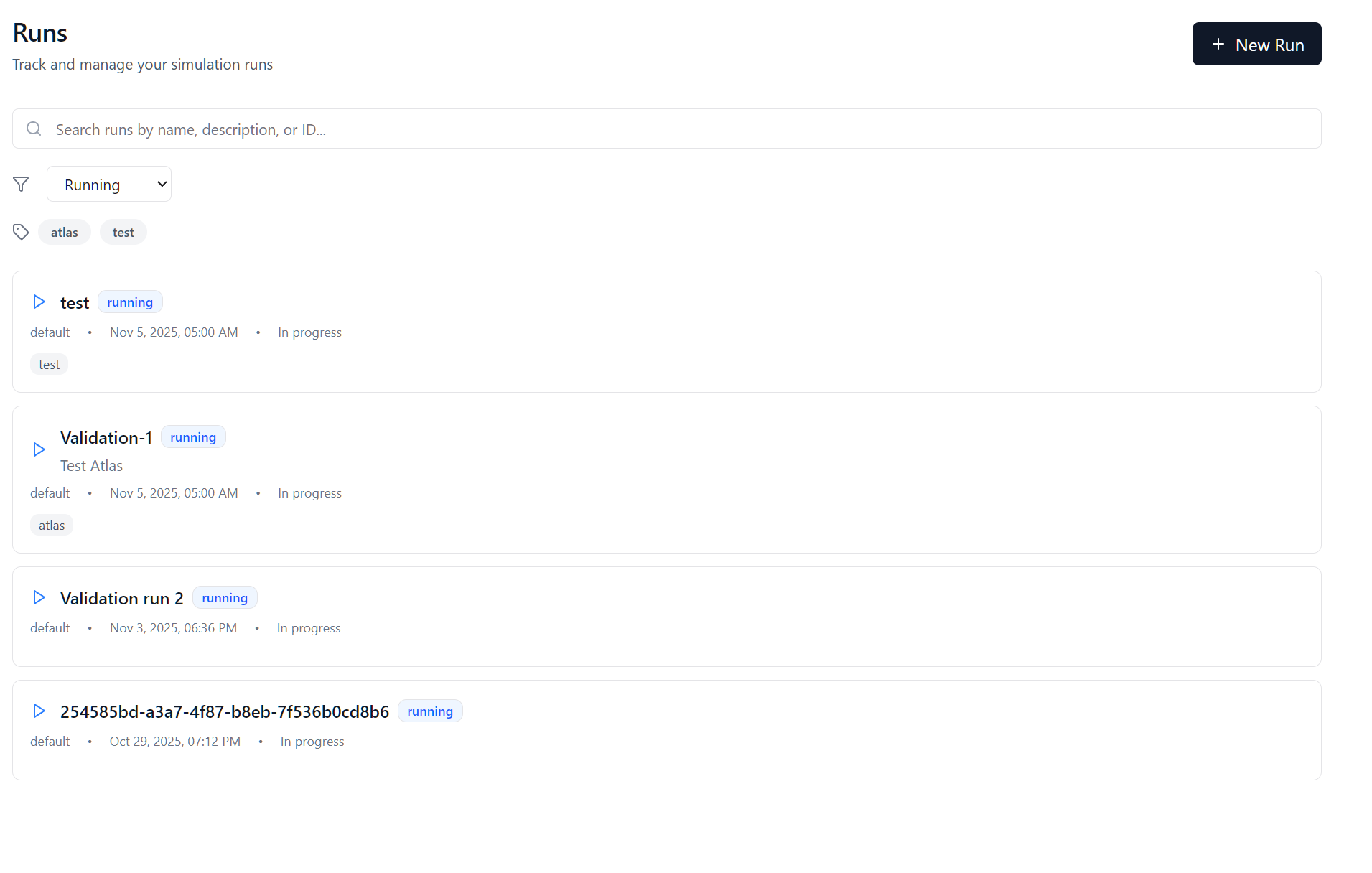
From the Run Main page, you can add new runs, or view the existing runs Click "Add Run" icon to create a new run
Using the GUI to create a new Run
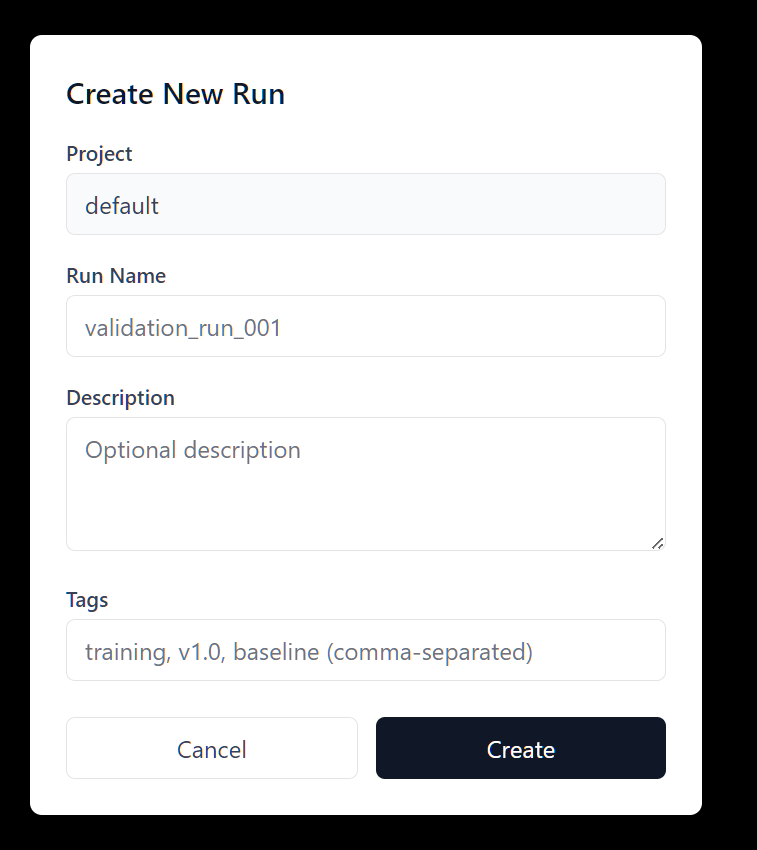
Add the Run name, and other optional details. You can add Tags to label your runs.
View the Run details in GUI
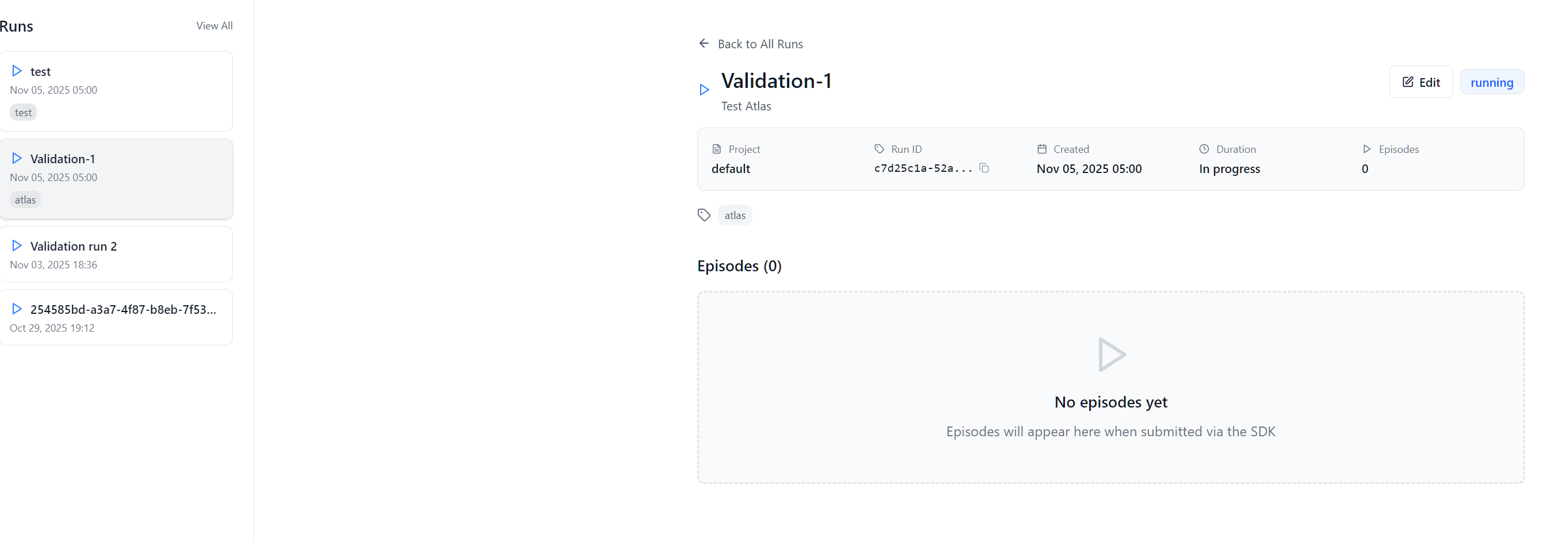
After creating a new run, or selected an exisiting run from the main page, you can view the current status or results of episodes.
Best Practices
-
Always Use Context Managers: Ensures proper cleanup
with run: # Your code -
Create Episodes in Batches: For large-scale experiments
with run: for batch in range(10): for i in range(100): with run.create_episode() as episode: # Process episode -
Handle Errors Gracefully: Always finish episodes even on errors
try: result = validate(config) episode.finish(EpisodeStatus.FINISHED) except Exception as e: episode.finish(EpisodeStatus.ERRORED, str(e)) -
Use Meaningful Names: Make runs easy to identify
run = hl.Run( scenario=scenario, name=f"param_sweep_{datetime.now().strftime('%Y%m%d_%H%M%S')}", description="Sweeping friction parameters", tags=["sweep", "friction", "v2"] ) -
Tag Your Runs: Use tags for organization and filtering
tags=["baseline", "physics", "experiment_1"]
Complete Example
import humalab as hl
from humalab.humalab_api_client import EpisodeStatus
# Initialize
hl.init(api_key="your_api_key")
# Create scenario
scenario = hl.scenarios.Scenario()
scenario.init(scenario={
"learning_rate": "${log_uniform: 0.0001, 0.1}",
"batch_size": "${categorical: [32, 64, 128], [0.3, 0.5, 0.2]}"
})
# Create run
run = hl.Run(
scenario=scenario,
project="hyperparameter_search",
name="lr_batch_sweep",
tags=["training", "optimization"]
)
# Execute episodes
with run:
for i in range(50):
with run.create_episode() as episode:
# Train model with sampled parameters
model = train_model(
lr=episode.learning_rate,
batch_size=episode.batch_size
)
# Log results
episode.log({
"accuracy": model.accuracy,
"loss": model.loss
})
# Cleanup
hl.finish()